
python的字典和集合的退化
Python 的字典 dict 和集合 set 以 hashable 作为 key,存储数据于其中,理想情况下,查询操作具有 $O(1)$ 的时间复杂度。但如果你想当然地认为,现实总是和理想差不太多,那么就可能会掉入一个陷阱之中。
| 操作 | 数组 (Array) | 链表 (Linked List) | 散列表 (Hash Table) |
|---|---|---|---|
| 增(插入) | $O(n)$ (中间) / $O(1)$ (末尾) | $O(n)$ (需要遍历) | 平均 $O(1)$ |
| 删(删除) | $O(n)$ (中间) / $O(1)$ (末尾) | $O(n)$ (需要遍历) | 平均 $O(1)$ |
| 查(查找) | $O(1)$ (按索引) / $O(n)$ (按值) | $O(n)$ | 平均 $O(1)$ |
| 改(修改) | $O(1)$ (按索引) | $O(n)$ | 平均 $O(1)$ |
Python 实现字典和集合,利用了 hash 表。存储元素到 hash 表时,首先会用散列函数对元素计算 hash 值,然后相同 hash 值的元素,会存储在同一个链表之中。这个 hash 函数,就是元素的类上所定义的 __hash__ 特殊方法,会以元素进行计算然后得到一个整数值。Python 判断一个元素是否在字典和集合中(__contains__),还要判断元素是否相等 (__eq__,默认比较元素的内存地址,即 id)。首先是找到元素的 hash 值所在的链表,然后对链表元素进行逐个比对,仅当相等时才认为元素在其中,在链表中查找的时间复杂度是 $O(n)$。也就是说,字典和集合在最坏情况下,查询的时间复杂度就是 $O(1 * n)$,即 $O(n)$。
这种情况就是 hash 冲突,当严重的冲突发生时,hash 表就退化为链表了。
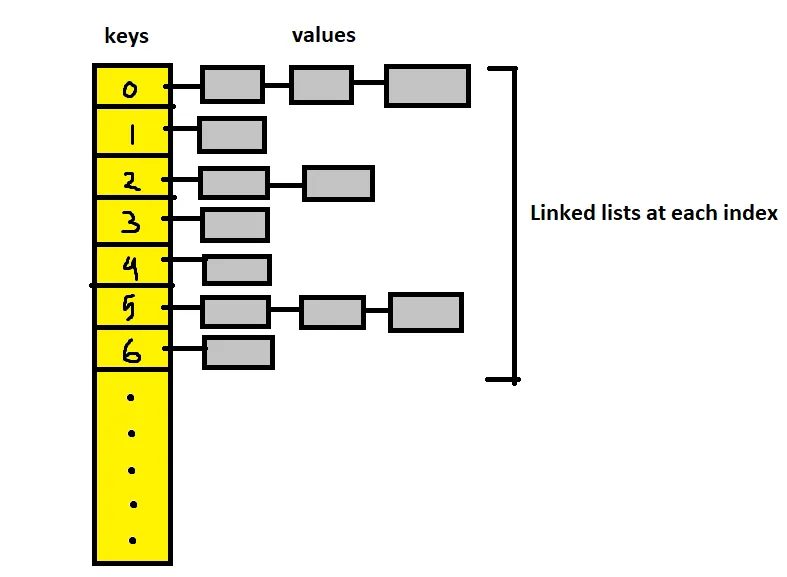
所以,如果一大堆元素有相同的 hash 值,则存储它们的字典或集合会发生退化。
现在假设你有这样一个类,它总是对任何实例,计算出的 hash 值为 0
1 | class A: |
然后分别创建列表、字典和集合,为了测量耗时,我在 IPython 中执行了代码。
1 | In [2]: %time list0 = [A() for _ in range(10000)] |
1 | In [3]: %time dict0 = {A(): None for _ in range(10000)} |
1 | In [4]: %time set0 = {A() for _ in range(10000)} |
可以看到,在集合和字典中新增元素,比在列表中慢的多得多,而集合比字典快一些,因为集合的结构更简单一些。之所以都比列表慢那么多,是因为集合和字典在新增、删除或修改时,也要先查询元素是否在其中,然后才能执行实际的操作,而在查询上退化为 $O(n)$,在新增、删除或修改 $n$ 个元素时,时间复杂度也会退化为 $O(n^2)$。
另外在 Python 中,列表的查询速度,却又比链表快一倍
1 | In [5]: %timeit A() in list0 |
1 | In [6]: %timeit A() in set0 |
1 | In [7]: %timeit A() in dict0 |
不过有趣的是,字典的查询速度,比集合快了一些。
python的字典和集合的退化
https://chenyanggao.github.io/2025/08/20/15.python的字典和集合的退化/



